Recentemente realizei o curso do Rafael Arruda no qual ele ensina com maestria, diga-se de passagem, a utilização dos recursos do Pentaho Data Integration, desde o básico até o armazenamento de dados na nuvem como a AWS. Recomendo muito.
Pois bem, chegou a hora da primeira utilização desta ferramenta em um cenário real, o qual eu estava com dificuldades há algum tempo e eu imaginava que ela poderia resolver: A extração de dados por uma API que utiliza paginação.
Continua lendo que eu te conto como fiz essa façanha!
O cenário
A empresa no qual trabalho utiliza o Pipefy para gerenciar seus processos internos e externos, como tarefas administrativas, financeiro, pedidos de compra, etc. Isso tudo é feito de maneira bem estruturada, sendo a principal forma de organização através do método Kanban. A ferramenta é realmente muito boa e eu tinha uma tarefa: Calcular o tempo médio de vida de cada card, desde sua criação até a conclusão, respeitando a taxa máxima de cards que podem sofrer atraso, o famoso SLA (Service Level Agreement). Além disso, eu deveria também ter outras métricas, como o tempo médio de cada card nas fases pelo qual ele passa, etc.
O problema
Eu obtinha o relatório de cards de cada pipe (contendo título, data de criação, data de finalização, campos em cada fase, etc) com certa naturalidade, bastando ir em cada pipe e baixando manualmente o arquivo xlsx gerado pelo site. Mas, convenhamos… Ninguém merece ficar baixando cada arquivo manualmente, né? Ainda mais tendo que entrar em cada pipe individualmente (eram mais de 30).
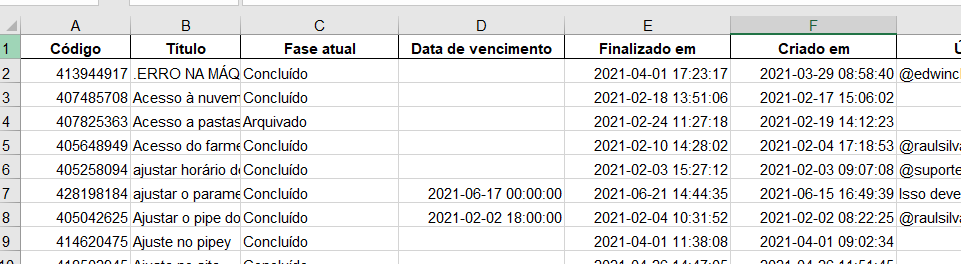
O Pipefy oferece uma maneira “rápida” de poder baixar estes arquivos de uma vez só, entretanto o xlsx baixado não diferencia os cards dos pipes, então, caso um determinado campo fosse utilizado em mais de um pipe, eu não saberia de qual pipe aquele campo pertencia. Ou seja, era inviável.
Em busca da solução perfeita (mas nem tanto)
Ao buscar alternativas a isso, me deparei com duas soluções bem mais viáveis:
1- Conector para o PowerBI
O Pipefy possui um conector (desenvolvido por terceiros) que faz todo o serviço de baixar os cards de todos os pipes, bastando colocar o id da organização e logar com minhas credenciais.
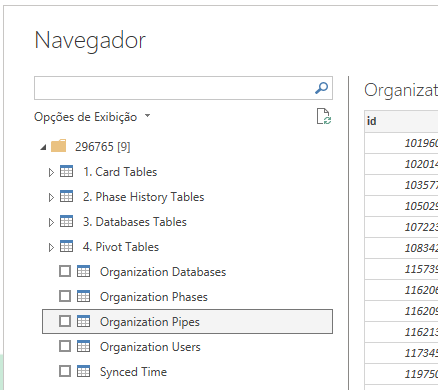
Parecia a solução mais simples e perfeita, com tudo funcionando redondinho. Mas aí veio o balde de água fria ao publicar no PowerBI Online: o plugin não tinha suporte a atualização.
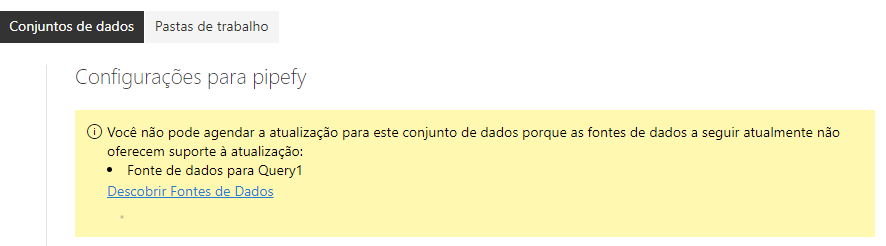
Ora, não faz nenhum sentido manter um relatório publicado se não é possível atualizá-lo, não é? Então eu tive que partir para a segunda solução.
2- Utilização de API REST (GraphQL)
A obtenção de dados via API é, sem sombra de dúvidas, a melhor forma de obter dados em tempo real sem a necessidade de baixar arquivos do servidor. Em uma única requisição você solicita o que deseja e também recebe a resposta de forma estruturada (no caso do Pipefy o retorno é um JSON).
O PowerBI até consegue trabalhar bem com API REST, deixando você manipular livremente a URL, Header e Body. Mas eu encontrei um problema que, na verdade, nem é do PowerBI em si e sim uma implementação do próprio Pipefy.
Ao fazer a request allCards, percebi que só vinham 50 cards e não mais que isso. Ao procurar o porquê disso, vi em fóruns que isso acontecia por causa de uma implementação chamada paginação.
O que é paginação?
De maneira simples, a paginação serve para impor um limite na quantidade de informações trazidas a cada solicitação feita pelo cliente. Isso é uma medida de proteção do lado do servidor para que ele não fique sobrecarregado e nem sofra ataques de negação de serviço: imagine mandar várias solicitações e o servidor ter que retornar 50.000 registros a cada uma delas? Buffer overflow na certa!
Da mesma forma que um livro é marcado com páginas, a paginação da API também funciona desta maneira: X registros são retornados, além de informações de cursor inicial, cursor final, e se há uma próxima página.

Caso o cliente queira obter informações desta próxima “página”, ele deve fazer uma nova solicitação, dessa vez contendo o cursor final onde a consulta anterior parou. Dessa forma ele retorna os outros registros e marca novamente o cursor final. Isso pode ser feita de forma cíclica, até momento que o indicador de próxima página se torna false. Isso indica que a consulta chegou ao fim e não há mais resultados a serem mostrados.
Ok, essa explicação toda tem um objetivo: o PowerBI simplemente não trabalha com paginação (pelo menos não de forma nativa). Então eu deveria recorrer a uma ferramenta que fizesse isso e entregasse os dados todos estruturados para o nosso querido programa de BI apenas fazer seu papel de elaborar os gráficos.
Mas qual ferramenta poderia fazer isso? 😢
Foi aí que surgiu o Pentaho Data Integration na minha vida! 😄
PDI, me salva!
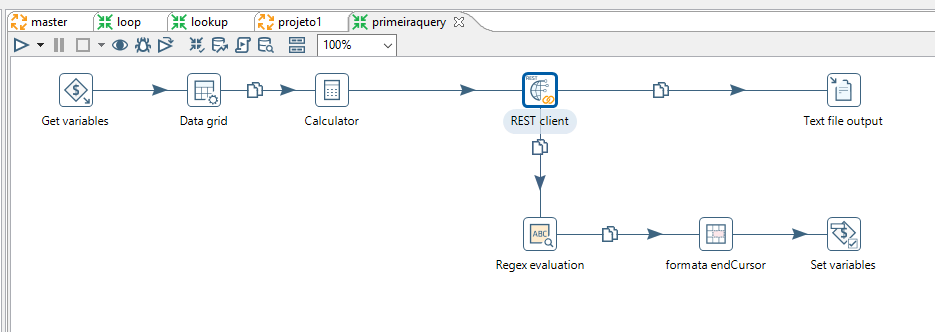
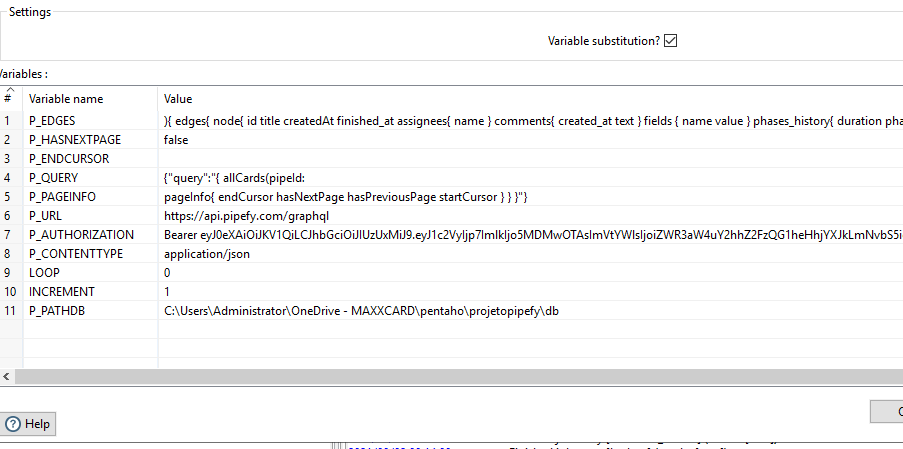
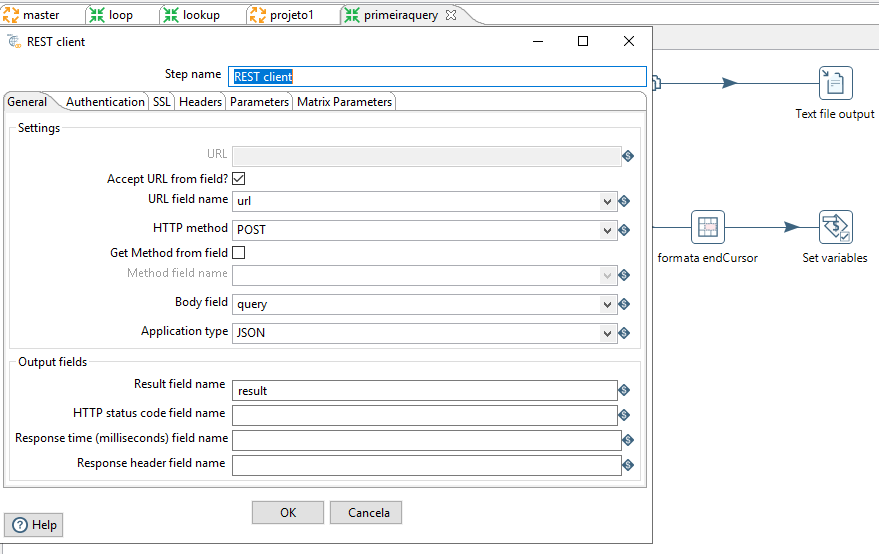
O Pentaho tem a vantagem de trabalhar em forma de “steps”, no qual cada fase (Transformação) é executada de forma ordenada no Job. A ideia que eu tive era do programa fazer uma solicitação, guardar os registros em um arquivo de texto e as informações de paginação em variáveis internas. Dessa forma, poderia ser feito um loop onde a solicitação seguinte já iria com o cursor inicial trazido pela requisição anterior e guardado na variável. O loop para quando a requisição retorna que não há mais registros a serem retornados.
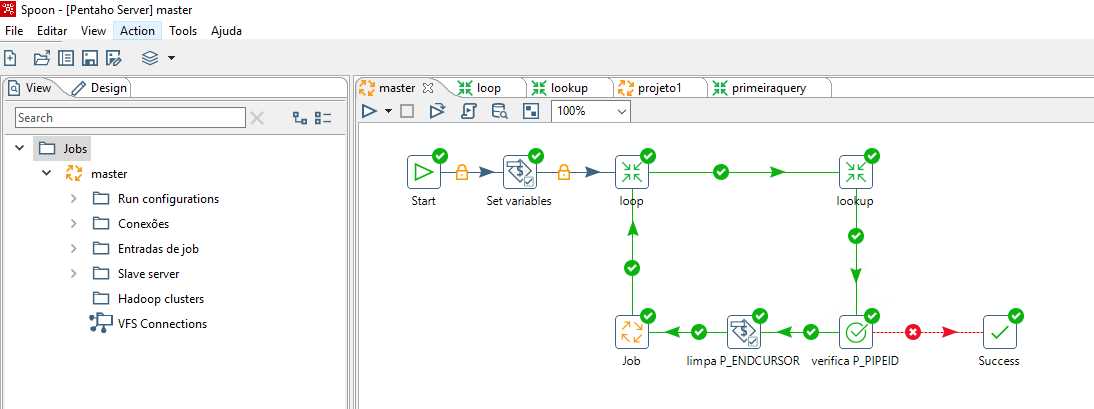
Colocando a mão na massa
A partir daqui, é um trabalho puramente de paciência e planejamento. Não irei entrar em tantos detalhes assim para que esse artigo não fique gigante, mas irei deixar as telas principais. Caso tenha vontade de entender melhor como isso funciona, deixe seu comentário. Quem sabe eu faça um post ou mesmo vídeo explicando direito como essa “budega” funciona. 😄 rsrs
Até mais!




Bom dia Edwin Chagas,
Sou Henrique, estudante de Engenharia Biomédica (UFPA) e de Eletrotécnica (IFPA), estou fazendo estágio numa empresa de energia solar e participo de um láboratório na faculdade. Bom, estava procurando alguma forma de linkar os Pipefy com o Power BI e achei o máximo a metodologia que o senhor utilizou, visto que ainda estou aprendendo a usar o Pipefy e verifiquei que ele não gera gráficos tão bons assim. Desta forma, queria entender melhor sobre funcionamento, sei que é o seu trabalho, mas queria poder implementar na minha região, pois ainda não há este tipo de cuidado com processos por aqui.
Desde já, agradeço a atenção.