
Se você acompanha o mercado de BI atualmente, principalmente com a ferramenta PowerBI, já deve ter visto centenas (ou milhares) de dashboards “bonitinhos”, utilizando as mais diversas fontes, ícones, imagens vetorizadas e cores chamativas que deixam os olhos de qualquer cliente brilhando. E realmente é essa finalidade do BI: traduzir a sopa de letrinhas que é um relatório em Excel ou PDF em algo mais agradável de se visualizar e de se analisar.
Entretanto, o que vejo pouca gente mostrando em seus relatórios é justamente a parte de trás, os bastidores, fórmulas DAX e M, além de não termos ideia da onde vieram aqueles dados (excel? banco de dados? csv? vozes da minha cabeça?)
O tratamento de dados é uma parte crucial do desenvolvimento de um dash, afinal de contas, do que serve algo extremamente bonito e agradável se os dados são mostrados da forma incorreta?
Por conta disso, irei trazer, ao longo das próximas semanas, conteúdos relevantes sobre tratamento de dados, principalmente ETL e DAX, para que suas análises sejam cada vez mais assertivas e promissoras.
Hoje irei mostrar um caso que me ocorreu recentemente onde tive que tratar uma tabela em Excel completamente bagunçada. Colunas fora do lugar, espaços em branco, caracteres estranhos…. dava até dó. Mas missão dada é missão cumprida.
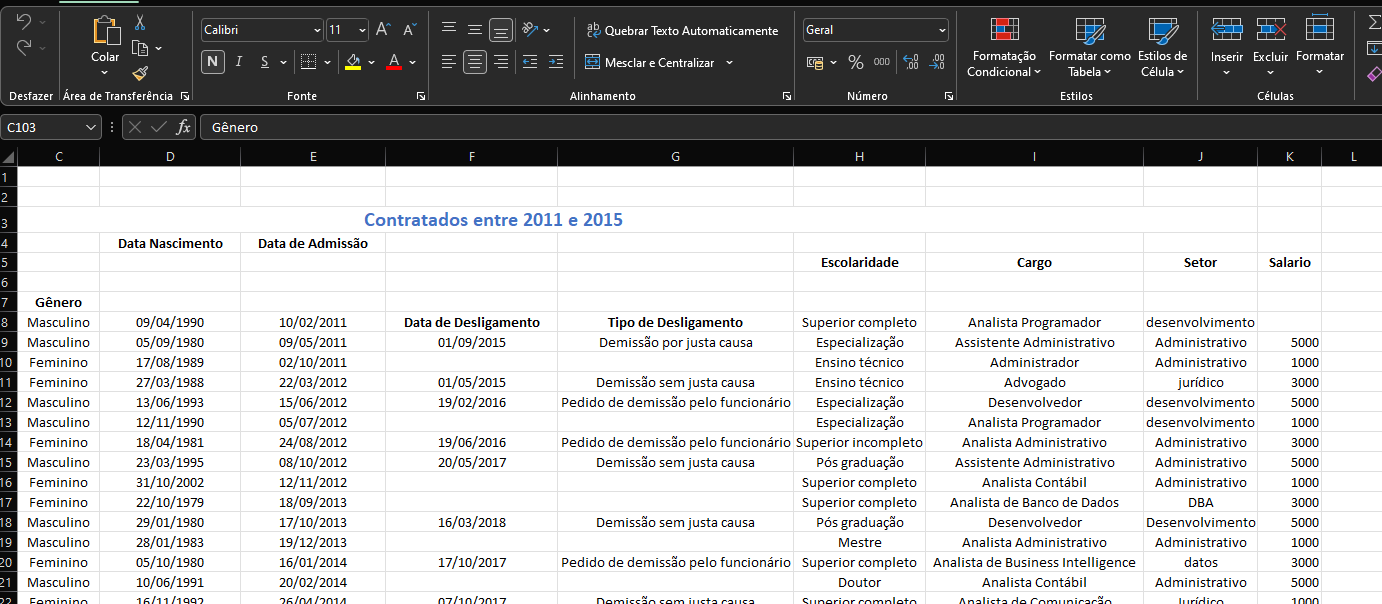
Repare como há diversos problemas aí: Cabeçalhos desalinhados, ausencia de valores, Título no lugar errado….
“Mas, Ed… é só fazer os ajustes no próprio Excel e tá tudo certo.”
Seria o mais lógico a se fazer, claro. Entretanto devemos ter em mente que este é apenas um exemplo. E se a empresa tiver outros arquivos tão bagunçados quanto este? Fariamos ajuste um a um? Não quero nem imaginar o trabalho que daria…
Pois bem. Vamos importar o arquivo no Power Query e ver como ele fica:
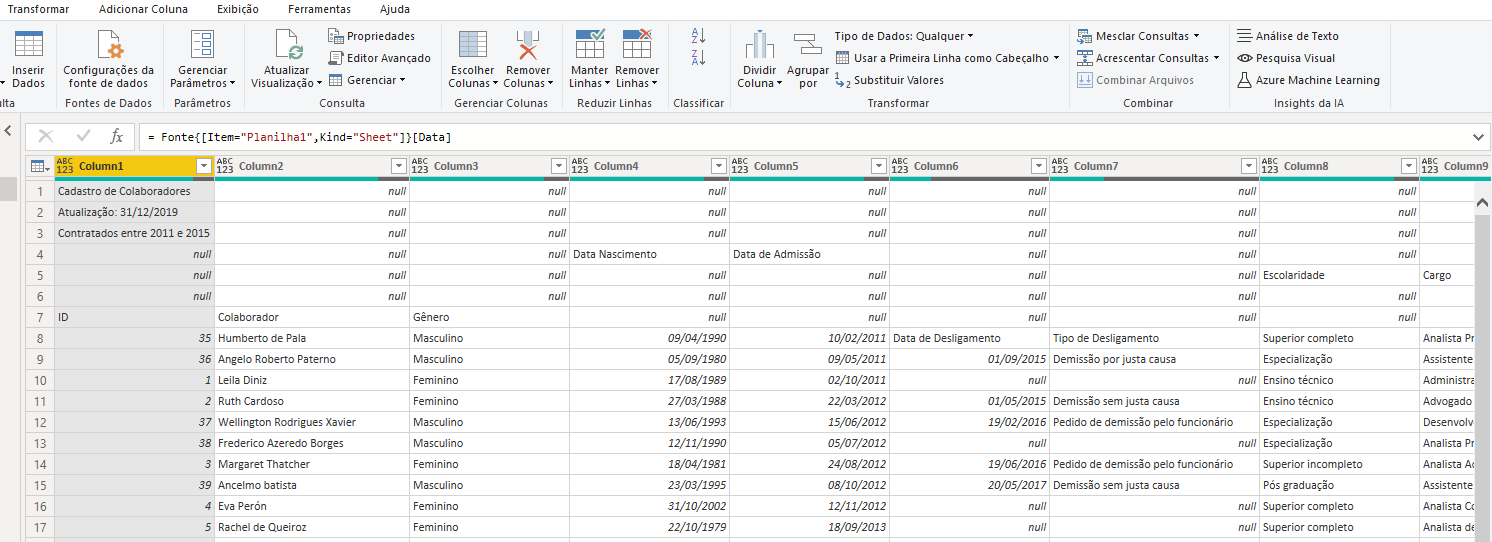
Como esperado, ficou bem bagunçado. Mas vamos dar um jeito:
Minha estratégia era duplicar este dataset e tratá-los de maneira independente: Em uma tabela eu iria isolar apenas os dados e em outra tabela eu iria isolar todos os cabeçalhos. Após isso, bastaria mesclar os dados à tabela de cabeçalho.
Tratando os dados
A primeira coisa que fiz foi acertar os tipos das colunas, definindo corretamente os que eram tipo numérico, data ou texto.
A primeira coluna é o id dos colaboradores, então defini ela como numérica. Como era de se esperar, deu erro em algumas linhas, mas aí bastaria remover estes
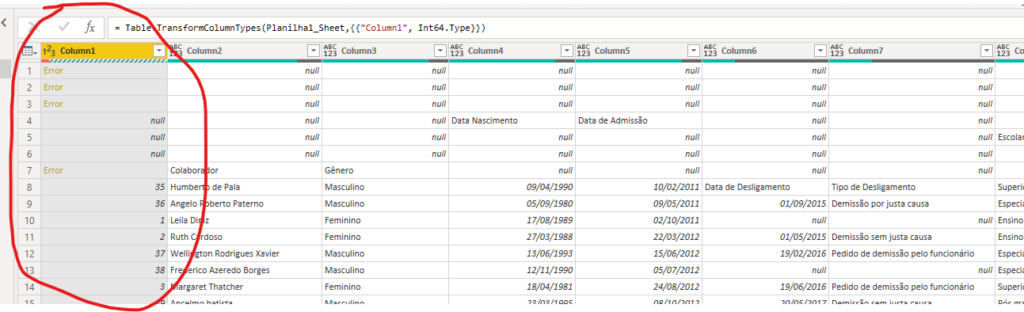
Após isso, eu removi todas as linhas com erros e que estavam nulas. Dessa forma, filtrei todas as linhas válidas.
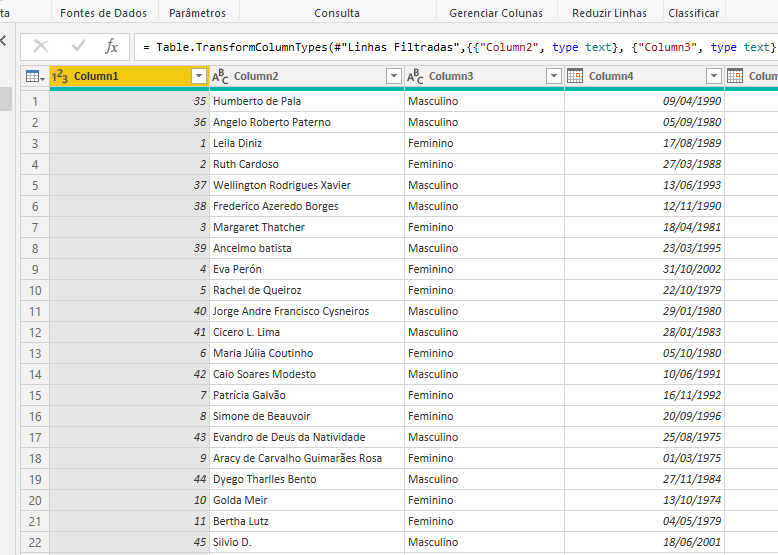
Alguns campos estavam com os cabeçalhos de colunas. Dessa forma apenas substituí os estes valores por null
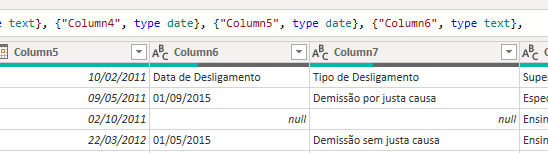

Tratando os cabeçalhos
Para encontrar os cabeçalhos e formata-los da forma correta, eu isolei as 5 primeiras linhas (a partir da terceira) na qual continha todos os dados que eu precisava

Como minha intenção era fazer com que todos os cabeçalhos estivessem na primeira linha, eu utilizei a função de preenchimento de valores para cima do M. Após isso, bastou manter apenas a primeira linha e voilá, eu já tinhas todos os cabeçalhos
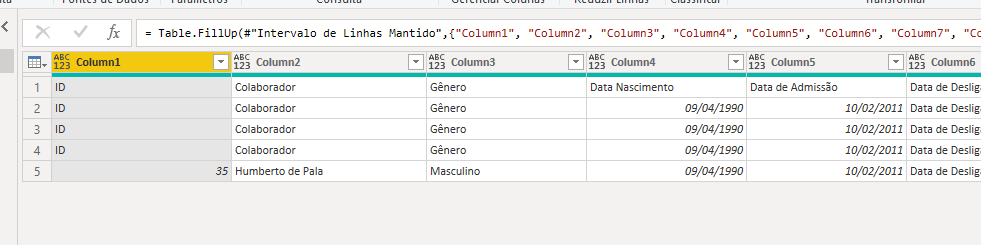

Após isso, ficou fácil né? Agora é só acrescentar os dados préviamente tratados e temos uma bela tabela
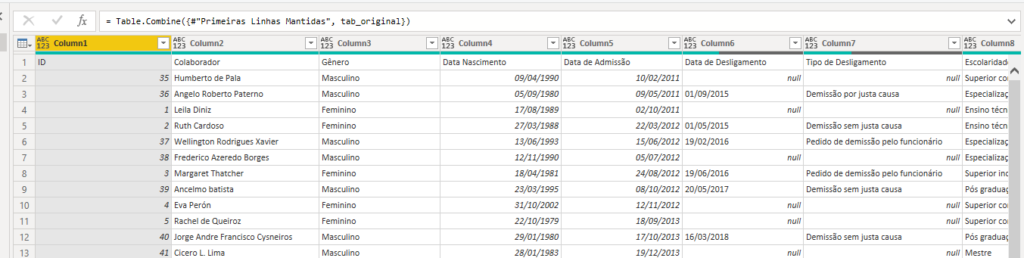
O toque final é promover os cabeçalhos e acertar os tipos de dados para que estejam na forma correta
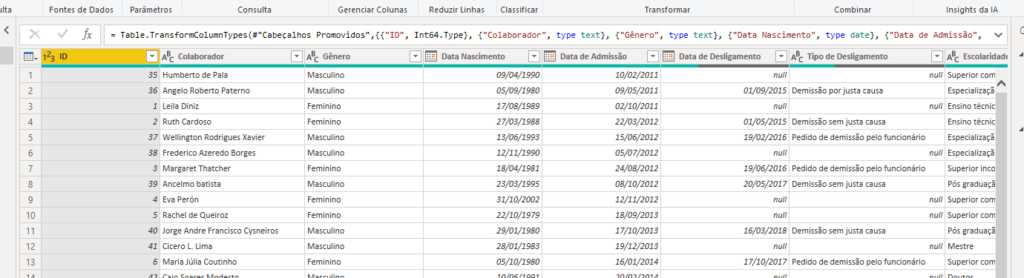
Dessa forma, pegamos uma tabela bem bagunçada e utilizamos apenas funções da linguagem M para que todo tratamento de dados fosse feito no PowerBI.
Agora é só importar para o seu relatório e fazer seus visuais. 😉
Compartilho com vcs como ficou meu projeto.
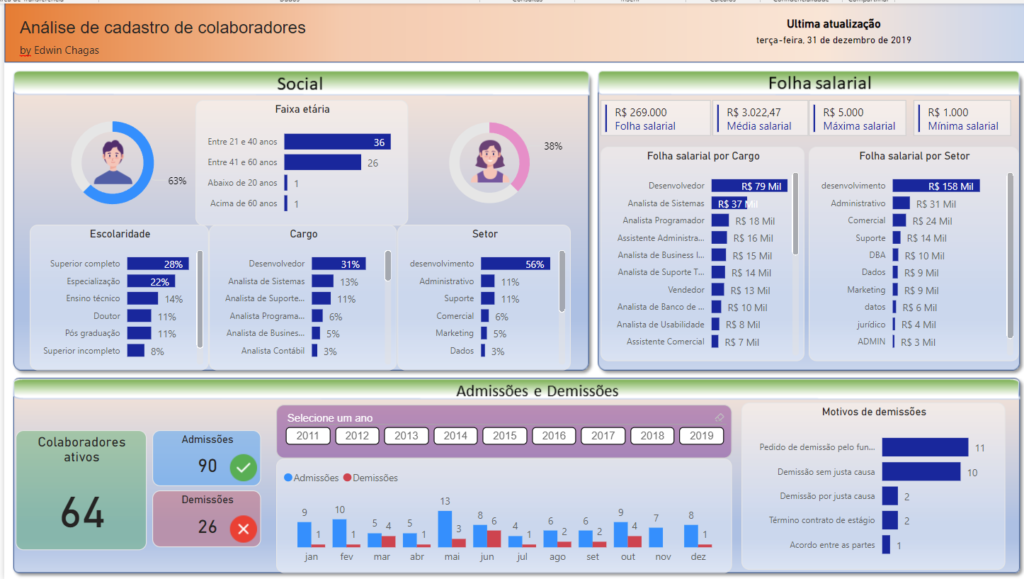
Esperam que tenham gostado e até a próxima! 😁👍



